Customer-Churn is the termination of a contract by the customer. Predicting such events before they occur is of great interest in many business areas. Focusing countermeasures on relevant customers reduces the effort and prevents a sleeper effect with customers who are not at risk.
One possible way of predicting churn will be shown here using decision trees from the SAP HANA Predictive Analysis Library (PAL). A data set of customer data from a telecommunications company with known churn events serves as the data basis.
The sleeper effect describes that customers only evaluate their contract conditions through the established contact and then cancel.
A decision tree separates the data set as precisely as possible into churn customers and non-churn customers. To do this, it creates decision rules for which it uses customer characteristics, such as "Monthly turnover > X" or "Use of streaming offers yes/no". The combination of the individual rules then finally allows the decision tree to assign a customer to churn/non-churn.

Figure 1: Section of a possible decision tree
The choice of parameters when creating a decision tree influences both the accuracy of the assignment and the complexity of the rules. If one sets the value of simplicity high, the rules become less specific, but the accuracy of the classification usually decreases. So there is a trade-off between readability and better separation.
Simplicity here describes the necessary number of clients described by a rule. If this value is not reached, the rule is not formed and further division ends in this branch.
For the creation of the decision tree and the verification of the created rules, training and test datasets are needed. In this example, the data set is in aDSO in SAP BW. Training set and test set are persisted as tables for comparability of runs from the data set. Data preprocessing and splitting was done using ABAP.
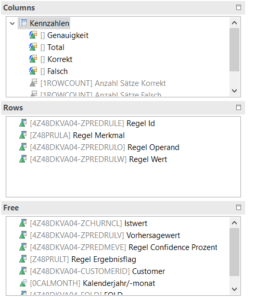
After creating the separated sets, the quality of the created decision trees is assessed first with the training set then with the test set. If the accuracy of the separation of churn and non-churn is satisfactory, a final decision tree is created based jointly on training and test data. The decision trees are created with a call to SAP HANA PAL in ABAP. The created and combined rules from the PAL are difficult to read without further formatting and are not yet assigned to individual customers. However, an insight is desirable for checking the correct application of the master and transaction data in the rules. In addition, looking at which rule applies to a customer can give clues as to which aspects can avert the churn event. Therefore, the rules are formatted in further ABAP programs and the applied rule is assigned to each customer. The formatted rules are merged with the customer data in aDSO and can be evaluated by query.
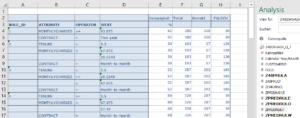
With a simplicity of 150, an accuracy of over 75% is achieved over the entire data set. However, looking at the rule level also allows the evaluation of the accuracy of the individual rules, which can also reach more than 90%.
Thus, churn prevention measures can be focused on vulnerable customers with sufficient predictive accuracy. This can reduce costs for sales measures and increase efficiency by avoiding false customer contacts.
Contact Person


")



